The AI Networking Wars: How Performance Rewrote the Competitive Hierarchy
Why NVIDIA dominates, who's fighting to stay relevant, and what the next disruption might look like



TLDR
· NVIDIA’s Strategic Dominance Through Integration: NVIDIA’s early recognition of AI’s unique networking demands led to its 2019 acquisition of Mellanox and integration of high-performance InfiniBand and NVLink technologies, enabling unparalleled GPU-to-GPU communication. By tightly coupling hardware and software through CUDA and NCCL, NVIDIA redefined performance metrics from "bandwidth per dollar" to "training time per model", securing a dominant 90% share of the AI training interconnect market.
· Traditional Players Struggle with Architectural Mismatches: Broadcom and Arista, once leaders in data center networking, face diminishing returns from Ethernet-based systems not designed for the east-west, latency-critical patterns of AI workloads. While both have introduced AI-specific products (e.g., Jericho3-AI and EOS upgrades), their efforts are hampered by the inherent limitations of Ethernet and lack of deep integration with AI compute platforms.
· The Next Disruption: Optics, Standards, and Architecture Shifts: Future threats to NVIDIA’s dominance include the shift to co-packaged optics (led by enablers like Credo), emergence of open interconnect standards (e.g., CXL, UCIe), and the rise of new AI architectures that could demand fundamentally different networking solutions. These developments may either fragment the market and benefit modular players—or be co-opted by platform giants like NVIDIA to entrench their leadership further.
When the Network Became the Bottleneck

In early 2020, researchers at a leading AI company faced a problem that would have seemed absurd to any network engineer just a few years earlier. Their flagship language model—the kind that would eventually power conversational AI systems—had been training for three weeks when the run suddenly stalled at 60% completion. Hundreds of GPUs sat idle across multiple server racks, burning through cloud credits at a rate that made CFOs weep.
The engineering team's first instinct was to check the obvious culprits. Compute utilization? 99%. Memory usage? Optimal. Storage I/O? Well within limits. Yet the training process had effectively frozen, with GPUs waiting for something that should have been nearly instantaneous.
The bottleneck, it turned out, wasn't any of the components that had defined computing performance for decades. It was the network.
More specifically, it was a network designed for a world where computers talked to other computers occasionally, not a world where thousands of processors needed to coordinate their every calculation in perfect synchronization. The traditional data center networking stack—built for web servers responding to user requests, databases serving applications, and storage systems moving files—simply couldn't handle AI's demands for collective communication patterns that no human application had ever needed.
This wasn't just a technical problem; it was an architectural mismatch that would reshape an entire industry. AI workloads didn't just need more networking—they needed fundamentally different networking. And in that difference lay the seeds of a competitive revolution that would elevate an unlikely player to dominance while leaving established giants scrambling to remain relevant.
Redefining the Network
To understand how AI transformed networking competition, it's essential to grasp what "AI networking" actually means, because it bears little resemblance to the networks that connect our laptops to WiFi or route traffic across the internet.
Traditional networking follows a relatively simple pattern: individual devices or applications make requests to other devices or services, typically following a client-server model where traffic flows north-south through network layers. A web browser requests a page from a server, a mobile app pulls data from an API, an email client connects to a mail server. Even in complex enterprise environments, network traffic largely consists of discrete transactions between specific endpoints.
AI training networks operate on entirely different principles. When training a large language model, thousands of GPU processors must work in perfect coordination, each one processing a small slice of the same massive dataset while continuously sharing their progress with every other processor in the cluster. This creates east-west traffic patterns where GPUs communicate primarily with their peers rather than with external services.
More critically, AI workloads depend on collective communication primitives—operations like "all-reduce" and "all-gather"—that require synchronized coordination across the entire cluster. When one GPU completes its calculation on a batch of data, it doesn't just send the result to a central coordinator; it participates in a carefully orchestrated exchange where every GPU simultaneously shares its results with every other GPU, combines the results mathematically, and begins the next iteration with the collective knowledge of the entire cluster.
The performance requirements are equally extreme. While traditional applications might tolerate network latencies measured in milliseconds, AI training requires responses measured in microseconds. A delay that would be imperceptible to a human user—say, a few milliseconds of additional latency—compounds across thousands of training iterations to add hours or days to model training time. When training the largest AI models costs millions of dollars in compute resources, those delays translate directly into massive cost increases.
Perhaps most importantly, AI's bandwidth requirements scale exponentially rather than linearly. Traditional applications generally scale their network usage in proportion to the number of users or the volume of data they process. AI models, however, require bandwidth that grows exponentially with model complexity. The jump from GPT-3 to GPT-4 didn't just double the networking requirements—it increased them by orders of magnitude.
This fundamental mismatch between AI requirements and traditional networking capabilities created an opportunity for companies that understood the implications early, while threatening those that had optimized for the old rules.
The New Hierarchy

NVIDIA: The Gravitational Center
When NVIDIA announced its $7 billion acquisition of Mellanox Technologies in 2019, the deal puzzled many industry observers. Why would a graphics processing company buy a networking firm? The transaction seemed like expensive diversification—a GPU vendor wandering far from its core competency into an adjacent market with different customers, different sales cycles, and different technical challenges.
The critics fundamentally misunderstood NVIDIA's strategy. The company wasn't buying a networking business; it was completing a platform.
NVIDIA had spent the previous decade building the computational infrastructure for AI workloads, but they recognized that computation alone wouldn't be sufficient for the massive distributed training runs that frontier AI models would require. The network between processors would become as critical as the processors themselves, and optimizing that network would require the same kind of full-stack integration that had made NVIDIA's GPUs dominant in AI training.

The Mellanox acquisition gave NVIDIA control over InfiniBand, a high-performance networking technology that had found success in supercomputing applications precisely because it prioritized latency and bandwidth over the compatibility and cost considerations that drove mainstream Ethernet adoption. InfiniBand's native support for remote direct memory access (RDMA) and hardware-accelerated collective operations made it naturally suited for AI workloads, but more importantly, it gave NVIDIA the ability to optimize networking and computing as a unified system.
NVIDIA's approach to AI networking reflects three key innovations that competitors have struggled to replicate.
First, NVLink provides direct GPU-to-GPU communication within server racks, allowing processors to share memory and coordinate computation as if they were a single, massively parallel machine.
Second, InfiniBand enables cluster-scale communication with sub-microsecond latency, connecting racks of GPUs with the kind of performance that traditional Ethernet simply cannot match.
Third, SHARP (Scalable Hierarchical Aggregation Protocol) performs AI operations directly in network switches, reducing the number of round trips required for collective communication.
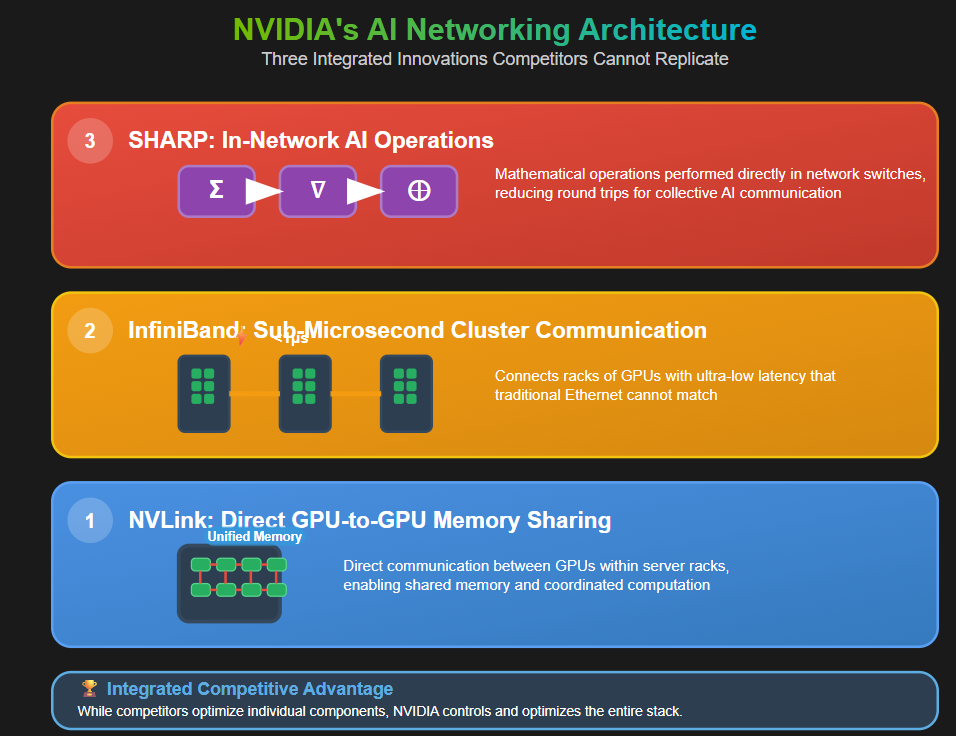
But perhaps NVIDIA's most important advantage lies in software integration. The company's CUDA programming framework and NCCL communication library are deeply optimized for NVIDIA's hardware architecture, creating a level of coordination between compute and networking that third-party solutions cannot achieve. When AI researchers design models, they increasingly think in terms of NVIDIA's capabilities and constraints, creating a feedback loop that reinforces the company's platform advantages.
The results speak for themselves. NVIDIA's networking revenue reached $5 billion with 64% sequential growth, and the company commands an estimated 90% share of high-performance AI training interconnects. More importantly, customers optimize their entire AI infrastructure around NVIDIA's architecture, creating switching costs that extend far beyond simple hardware procurement.
NVIDIA succeeded by reframing the economic calculation that drives networking decisions. Instead of optimizing for "bandwidth per dollar"—the traditional metric that favored commodity Ethernet solutions—they shifted the conversation to "training time per model." This reframing made their integrated approach economically compelling rather than just technically superior, because reducing training time by even small percentages could save millions of dollars in compute costs.
Broadcom and Arista: Fighting Physics

The emergence of AI networking created fundamentally different challenges for the two leading traditional networking companies, even though both found themselves competing for the same customers who were rapidly scaling AI infrastructure.
Broadcom built its dominance in hyperscale networking around the Tomahawk series of Ethernet switching chips, which power an estimated 70% of the world's largest data centers. The company's success stemmed from a design philosophy that prioritized programmability and flexibility—Tomahawk switches could adapt to different workloads, support various protocols, and evolve as network requirements changed. This flexibility justified premium pricing and created customer loyalty in environments where networking needs were diverse and unpredictable.
AI workloads, however, expose programmability as a liability rather than an asset. Every layer of abstraction, every configuration option, and every protocol translation adds latency that AI applications simply cannot tolerate. The features that made Tomahawk dominant in traditional data centers—the ability to inspect packets, apply complex policies, and support multiple traffic types simultaneously—become performance penalties when applied to AI traffic that needs to move between GPUs as quickly as possible.
Broadcom's response reveals both the company's technical capabilities and the structural challenges they face. The Jericho3-AI represents a purpose-built solution for AI workloads, with simplified packet processing and optimized latency characteristics. The company has also embraced open-source network operating systems like SONiC, enabling partners to develop AI-specific optimizations without requiring Broadcom to build those capabilities internally.
Yet Broadcom remains in a fundamentally defensive position, working to prevent complete displacement by InfiniBand rather than establishing technical leadership in AI networking. The company's customers—particularly hyperscale cloud providers—prefer Ethernet for operational reasons, providing Broadcom with a market opportunity despite InfiniBand's technical advantages. This customer preference gives Broadcom a foundation to build upon, but it doesn't address the fundamental physics limitations that make Ethernet suboptimal for AI workloads.
Arista faces a different but related challenge. The company built its reputation on EOS, a network operating system that abstracted hardware complexity and enabled rapid innovation in network services. EOS allowed Arista to add features and fix problems through software updates rather than hardware replacements, making the company the preferred choice for cloud-native organizations that wanted to treat networking like any other software-defined infrastructure.

EOS remains a genuine competitive advantage in environments where networking requirements are complex and rapidly changing. Arista was the fastest traditional networking vendor to recognize AI's implications and develop specific solutions for AI workloads. The company's 7800R3 series switches incorporate hardware optimizations for reduced latency, while EOS has been enhanced with AI-specific traffic engineering and collective operation optimization.
However, software sophistication cannot overcome the fundamental physics constraints that limit Ethernet's performance in AI applications. EOS can optimize traffic flows and reduce software overhead, but it cannot eliminate the latency penalties imposed by Ethernet's protocol stack or the bandwidth limitations imposed by standard switching architectures. Arista's software-first approach hits performance ceilings in cutting-edge AI deployments, even as it continues to provide value in hybrid environments where traditional and AI workloads coexist.
Both Broadcom and Arista benefit from a crucial market dynamic: customer resistance to vendor lock-in. Even when NVIDIA's solutions deliver superior performance, many organizations prefer to maintain vendor optionality and operational consistency. This preference creates opportunities for Ethernet-based solutions that perform adequately rather than optimally, particularly as AI workloads become more diverse and performance requirements vary across different applications.
The strategic tension between performance and familiarity will likely determine how the market evolves. If AI performance requirements continue to increase exponentially, technical optimization will eventually override operational preferences. If AI workloads diversify and performance requirements plateau, operational considerations might create space for traditional networking approaches to remain competitive.
Marvell and Credo: The Critical Enablers
The platform battle between NVIDIA, Broadcom, and Arista has overshadowed the important roles played by companies that enable AI networking without controlling it. Marvell and Credo Technologies represent two different approaches to this enabling position, each providing essential capabilities while depending on others for market success.
Marvell occupies the challenging position of a component supplier in an increasingly platform-driven market. The company possesses genuine technical expertise in areas directly relevant to AI networking: DPU (Data Processing Unit) design, custom silicon development, and specialized processors for edge computing applications. Marvell's automotive networking experience has given them deep understanding of latency-critical applications, while their storage controller business provides insights into high-performance I/O optimization.

In AI networking, Marvell's most significant opportunity lies in DPUs and smartNICs that offload network processing from CPUs in AI clusters. As AI inference workloads scale beyond training applications, the economics of specialized processing become compelling for cost-sensitive deployments. Marvell's expertise in custom silicon could also enable AI-specific networking chips optimized for particular applications rather than general-purpose switching.
However, Marvell faces the fundamental challenge that affects all component suppliers in platform markets: the economics of integration increasingly favor companies that control complete systems rather than individual components. Platform providers can optimize across hardware and software boundaries in ways that component suppliers cannot match, and they can capture more value from the integrated solutions that customers increasingly prefer.
Marvell's path forward likely depends on whether AI networking requirements fragment into specialized niches that platform providers cannot economically address, or whether continued consolidation around integrated platforms leaves little room for independent component suppliers. The growth of edge AI applications, with their different performance and cost requirements, may create opportunities for Marvell's modular approach to compete effectively against integrated platforms optimized for data center deployment.
Credo Technologies occupies a different kind of enabling position, one that may prove more strategically valuable over time. The company specializes in SerDes IP and optical signal processing technologies that enable co-packaged optics (CPO)—a technology that could fundamentally change the economics of AI networking by eliminating the copper interconnects that currently limit performance and power efficiency.

AI's bandwidth requirements are pushing copper interconnects toward their physical limits. NVIDIA's NVLink technology requires over three miles of copper cable per server rack, creating heat generation, signal degradation, and power consumption challenges that compound with every increase in performance requirements. Each digital signal processor and retimer added to maintain signal quality introduces cost and latency penalties that eventually make copper-based solutions uneconomical.

Co-packaged optics represent a potential solution to these limitations by placing optical transceivers directly adjacent to AI processors, eliminating copper interconnects entirely for the highest-performance connections. This approach promises higher bandwidth density, lower power consumption, and better signal integrity, but it requires sophisticated packaging technologies and signal processing capabilities that few companies possess.
Credo's position in enabling the optical transition resembles ARM's role in mobile processors or TSMC's position in semiconductor manufacturing—they provide essential technology that enables the broader ecosystem without controlling platform decisions. This position offers both opportunities and limitations: Credo benefits regardless of which platform provider ultimately dominates AI networking, but their success depends on the timing and pace of the optical transition, which is largely determined by others.
The optical transition also illustrates a broader pattern in technology competition: even in platform-dominated markets, critical enabling technologies can maintain independent strategic value when they solve fundamental problems that all platform providers face. Credo's success will depend on whether the transition to optical interconnects occurs quickly enough to create substantial value before alternative solutions emerge.
Cisco: The Architectural Mismatch
Cisco's struggle in AI networking illustrates how technological shifts can render even the strongest competitive positions irrelevant when new requirements fundamentally conflict with existing architectural assumptions.
For decades, Cisco dominated enterprise networking by building solutions optimized for the complex, heterogeneous environments that characterize traditional IT infrastructure. Cisco's switches and routers excel at handling diverse traffic types, implementing sophisticated security policies, supporting multiple protocols simultaneously, and providing the kind of comprehensive management and monitoring capabilities that enterprise IT teams require.
These capabilities reflect deep investments in protocol stacks, feature sets, and software architectures that enable Cisco's equipment to handle virtually any networking requirement an enterprise might have. The company's success stemmed from solving the integration and compatibility challenges that made enterprise networking complex, providing solutions that worked reliably in environments where networking needs were diverse and often unpredictable.
AI networking requirements, however, directly conflict with the design principles that made Cisco successful in enterprise markets. The protocol processing, security features, and traffic management capabilities that enterprise customers value all add latency that AI workloads cannot tolerate. The flexibility that allows Cisco equipment to support diverse applications becomes a performance penalty when applied to AI traffic that has very specific, predictable requirements.
More fundamentally, Cisco's solutions are optimized for north-south traffic patterns where clients communicate with servers through multiple network layers, while AI workloads generate primarily east-west traffic where processors communicate directly with their peers. The network architectures, traffic engineering approaches, and optimization strategies that work well for traditional enterprise applications are simply not relevant to AI's requirements.
Cisco's attempts to address AI networking requirements have been limited by these architectural constraints. The company's Silicon One initiative represents an effort to build competitive switching silicon, but it lacks the AI-specific optimizations that would be necessary to compete effectively with purpose-built solutions. Software adaptations to existing platforms can reduce some inefficiencies, but they cannot eliminate the fundamental mismatch between enterprise networking architectures and AI performance requirements.
Perhaps more importantly, Cisco's sales and support model is optimized for enterprise relationships rather than the hyperscale procurement processes that drive AI infrastructure decisions. The company's strength in building long-term partnerships with IT teams becomes less relevant when purchasing decisions are driven primarily by technical performance benchmarks rather than relationship factors.
This doesn't mean Cisco is irrelevant to AI's future—the company likely retains opportunities in edge AI deployments where enterprise relationships and existing infrastructure integration matter more than absolute performance. But in the core AI training and inference applications that drive the highest-value networking decisions, Cisco's architectural approach and market focus leave them fundamentally misaligned with customer requirements.
The Technology Battlegrounds

The competition for AI networking dominance plays out across several distinct technical dimensions, each representing a different aspect of the fundamental challenge of enabling thousands of processors to work together as efficiently as possible.
The most visible battleground centers on interconnect architecture—the choice between InfiniBand and Ethernet as the foundation for AI cluster networking. InfiniBand offers clear technical advantages: native support for remote direct memory access (RDMA), hardware-accelerated collective operations, and sub-microsecond latency that Ethernet cannot match. These capabilities translate directly into faster training times and more efficient resource utilization for AI workloads.
Ethernet's advantages are operational rather than technical. Hyperscale operators understand Ethernet's behavior characteristics, have developed operational procedures around Ethernet equipment, and prefer to maintain consistency across their infrastructure. Ethernet also benefits from massive economies of scale across enterprise and cloud deployments, creating cost advantages that can offset some of the performance penalties.
The tension between performance and familiarity will likely be resolved by the specific requirements of different AI applications. Training frontier models where performance directly determines economic viability will continue to favor InfiniBand, while inference applications with more diverse performance requirements may find Ethernet solutions adequate.
Collective operations represent another crucial battleground where hardware acceleration competes with software optimization. NVIDIA's SHARP technology performs AI operations directly in network switches, reducing the number of communication rounds required for operations like gradient averaging across multiple GPUs. This approach requires tight integration between networking hardware and AI software stacks, creating advantages that are difficult for other vendors to replicate.
Traditional networking vendors have responded with software-based optimizations like enhanced RDMA over Converged Ethernet (RoCE) implementations and AI-aware traffic engineering in network operating systems. These approaches can improve performance compared to standard Ethernet deployments, but they cannot match the efficiency of purpose-built hardware acceleration.
The optical transition represents perhaps the most important long-term battleground, because it addresses the fundamental physics limitations that constrain all copper-based interconnects. As AI models continue to grow in size and complexity, the bandwidth and power requirements will eventually make copper interconnects uneconomical regardless of how well they are optimized.
Co-packaged optics promise to bypass these limitations by eliminating copper connections for the highest-performance links, but the technology requires sophisticated integration between optical components, packaging technologies, and system design. The companies that successfully navigate this transition will likely establish advantages that persist for the next generation of AI infrastructure.
Software integration may ultimately prove the most decisive battleground, because it determines how effectively networking hardware can be optimized for specific AI workloads. NVIDIA's advantage in this area stems from controlling both the compute and networking sides of the equation, enabling optimizations that span traditional component boundaries.
Competitors attempting to match this integration face a fundamental challenge: they must either build complete platforms that compete directly with NVIDIA's integrated approach, or they must convince customers to accept the performance compromises that come with multi-vendor solutions. The success of either approach will depend on whether AI requirements continue to favor integration or whether they diversify in ways that create opportunities for specialized solutions.
Customer Perspectives

The hierarchy of AI networking vendors reflects the diverse priorities and constraints of different customer segments, each of which evaluates solutions based on different combinations of performance requirements, operational preferences, and strategic considerations.
Hyperscale cloud providers represent the most sophisticated customer segment, with the technical expertise and purchasing power to evaluate solutions purely on their merits. These organizations prefer vendor diversity to maintain negotiating leverage and avoid strategic dependencies, but they are also driven by performance requirements that increasingly favor integrated solutions over modular approaches.
The result is a complex dynamic where hyperscalers adopt NVIDIA's solutions despite preferring alternatives, retain Broadcom relationships despite performance trade-offs, and embrace Arista innovations when they can achieve adequate performance with operational consistency. This customer segment's preferences create the primary market opportunity for traditional networking vendors attempting to compete with NVIDIA's integrated approach.
AI-native companies operate under different constraints. Organizations like OpenAI, Anthropic, and other frontier AI developers optimize primarily for training performance, because reducing training time directly impacts their ability to compete in rapidly evolving markets. These customers typically prefer integrated solutions that deliver maximum performance with minimal operational complexity, making them natural customers for NVIDIA's platform approach.
However, as AI-native companies scale their operations, cost optimization becomes increasingly important, creating potential opportunities for alternative solutions that offer better price-performance ratios even if they don't deliver absolute maximum performance. The challenge for traditional networking vendors is developing solutions that can compete effectively on cost without sacrificing too much performance.
Traditional enterprises represent a different market entirely, with AI networking requirements that are often secondary to broader infrastructure considerations. These organizations typically prefer solutions that integrate well with existing infrastructure, maintain consistency with operational procedures, and provide clear migration paths from current deployments.
This segment creates opportunities for vendors like Cisco and Arista that can offer AI capabilities as extensions of existing networking platforms rather than requiring complete infrastructure replacement. The performance requirements in enterprise AI deployments are also often less extreme than those in frontier model training, creating space for solutions that optimize for factors other than absolute performance.
The customer perspective reveals why multiple vendors can succeed in AI networking despite NVIDIA's technical leadership: different customer segments have different priorities, and those priorities create opportunities for solutions that optimize for factors other than pure performance. The key strategic question is whether AI requirements will converge around performance optimization or whether they will diversify in ways that sustain multiple competitive approaches.
Future Disruptions
Three potential disruption vectors could fundamentally alter the current competitive hierarchy in AI networking, each representing a different type of technological or market shift that might reset the advantages that currently favor platform approaches.
The optical transition represents the most immediate potential disruption, because it addresses fundamental physics limitations rather than incremental optimization challenges. When copper interconnects demonstrably limit the scaling of next-generation AI models, the transition to co-packaged optics becomes economically necessary rather than technically desirable.
This transition could benefit companies like Credo and Marvell that have invested in optical technologies, while potentially reducing the integration advantages that currently favor NVIDIA's platform approach. If optical interconnects can be standardized in ways that enable interoperability between different vendors' components, the transition might restore some of the modularity that characterized networking before AI's integration requirements.
However, the optical transition could equally strengthen platform providers if they successfully integrate optical technologies into their existing advantages. NVIDIA's approach to optical integration will likely determine whether this transition creates opportunities for competitors or reinforces existing platform advantages.
Open standards represent a different type of potential disruption, one that could enable the benefits of integration without the lock-in effects that currently characterize platform competition. Technologies like UCIe and CXL promise to standardize high-performance interconnects in ways that could enable mixing components from different vendors without performance penalties.
If these standards achieve real adoption and deliver on their performance promises, they could restore competitive dynamics to favor best-of-breed component selection rather than integrated platforms. Component specialists would benefit from renewed opportunities to compete on technical merit, while customers would gain vendor flexibility without sacrificing performance.
The challenge with standards-based disruption is that platform providers have strong incentives to resist standardization that reduces their advantages, and they often have the market power to prevent standards adoption if they choose to do so. The success of open standards will likely depend on whether customers collectively demand interoperability strongly enough to override platform providers' preferences.
Alternative AI architectures represent the most speculative but potentially most disruptive vector, because they could invalidate the fundamental assumptions that drive current networking optimization. Neuromorphic computing, quantum-classical hybrid systems, and in-memory processing approaches all have different communication requirements that might favor different networking solutions.
If alternative AI architectures prove superior for important applications, they could create opportunities for networking vendors that are not optimized for current GPU-centric approaches. The challenge is that architectural shifts typically take years or decades to achieve meaningful adoption, making them difficult to predict or prepare for.
More likely, alternative architectures will create specialized niches rather than replacing current approaches entirely. These niches might provide opportunities for companies that cannot compete effectively in mainstream AI training applications but can optimize for specialized requirements.
What This Means
The transformation of networking competition around AI requirements offers insights that extend beyond the specific technologies and companies involved, illustrating broader patterns in how platform competition evolves when technological shifts change fundamental requirements.
For investors, the AI networking hierarchy demonstrates both the durability and the fragility of platform advantages. NVIDIA's integration benefits create genuine competitive moats that are likely to persist as long as current AI architectures remain dominant, but those same advantages could become constraints if requirements change in ways that favor different approaches.
Platform positions offer the potential for substantial returns during periods when integration advantages are most valuable, but they also create concentration risks that become apparent only when technological transitions expose platform limitations. The timing of technological transitions—optical adoption, standards emergence, or architectural shifts—will largely determine investment returns across the sector.
Technology leaders evaluating vendor choices should recognize that networking decisions increasingly determine what AI applications are economically viable rather than simply affecting the cost or performance of predetermined applications. The choice between integrated platforms and modular approaches reflects fundamental trade-offs between optimization and flexibility that extend far beyond technical considerations.
Organizations should evaluate their networking strategies based on how directly performance impacts their business outcomes, their tolerance for operational complexity, and their assessment of how quickly their requirements might change. The current hierarchy favors organizations that prioritize performance and can accept vendor concentration, but future shifts might reward different strategic choices.
For entrepreneurs and innovators, the AI networking transformation illustrates how platform competition creates both opportunities and challenges for new entrants. Platforms typically resist disruption through incremental innovation, but they can be vulnerable to architectural shifts that change fundamental requirements or enable new approaches to longstanding problems.
The most promising opportunities likely exist in enabling technologies that solve problems for multiple platform providers, rather than in direct platform competition. The optical transition, edge AI scaling, and alternative architectures all represent areas where new approaches might create value regardless of which current platforms ultimately succeed.
The Network Architecture No One Predicted
NVIDIA's dominance in AI networking represents more than a successful product strategy—it demonstrates how platform thinking can reshape entire industries when technological shifts change fundamental requirements. The company didn't just ride the AI wave; they anticipated and built the infrastructure that made the wave possible.
The transformation reveals key principles about platform competition that apply beyond networking or AI. Winners don't just build better components; they redefine the metrics that define success and create switching costs through performance optimization rather than contractual restrictions. NVIDIA succeeded by changing the conversation from "bandwidth per dollar" to "training time per model," making their integrated approach economically compelling rather than just technically superior.
But perhaps the most important lesson is about the impermanence of competitive advantages. The same optimization focus that drives NVIDIA's current dominance—the tight integration between compute and networking, the software ecosystem that assumes specific hardware capabilities, the platform approach that prioritizes performance over modularity—could become constraints if AI requirements evolve in unexpected directions.
The optical transition, alternative architectures, or regulatory interventions could all reshape competitive dynamics in ways that favor different approaches. Edge AI applications with different performance profiles might create opportunities for modular solutions. New computational paradigms might require networking capabilities that current platforms don't provide. Open standards might eventually deliver integration benefits without platform lock-in.
The greatest risk in platform competition isn't falling behind current requirements—it's optimizing perfectly for a world that's about to change. NVIDIA's networking success stems from recognizing this principle early and building infrastructure for AI requirements before most competitors understood what those requirements would be.
The next chapter in AI networking will be written by companies that can anticipate the next set of requirements that seem impossible today but will seem inevitable in retrospect. Whether that's optical networking that makes copper interconnects as obsolete as dial-up modems, distributed architectures that eliminate the need for centralized training, or entirely new computational approaches that we haven't yet imagined.
The transformation of networking around AI requirements is just beginning. The companies that succeed in the next phase will be those that recognize when the current optimization targets are about to change and position themselves for the requirements that will define the next generation of intelligent systems.
In technology platform competition, the greatest victories go not to those who perfect yesterday's solutions, but to those who build tomorrow's infrastructure while everyone else is still solving yesterday's problems.
#AI #Networking #NVIDIA #DataCenters #CloudInfra #AIInfrastructure #DeepLearning #FutureOfAI NVDA 0.00%↑ AVGO 0.00%↑ MRVL 0.00%↑ CRDO 0.00%↑ ANET 0.00%↑ CSCO 0.00%↑ SMH 0.00%↑ SOXX 0.00%↑
Great piece. Thanks.
Wonderfully written. Changed my way of looking at the developments in the industry.